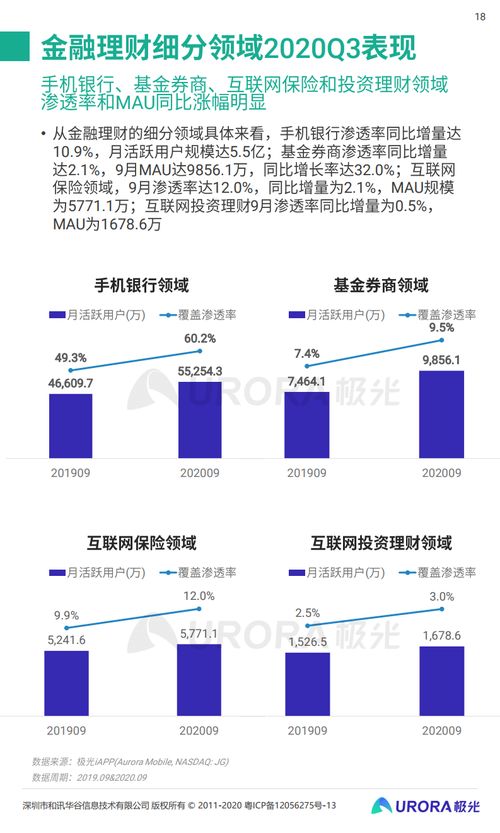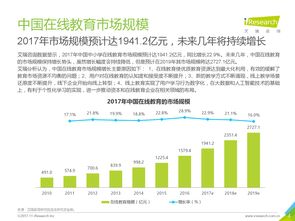
在當(dāng)今數(shù)據(jù)驅(qū)動的互聯(lián)網(wǎng)時代,業(yè)務(wù)系統(tǒng)產(chǎn)生的海量日志是洞察用戶行為、監(jiān)控系統(tǒng)健康、驅(qū)動智能決策的寶貴資產(chǎn)。實(shí)現(xiàn)日志的實(shí)時收集與實(shí)時計算,已成為提升業(yè)務(wù)敏捷性與競爭力的關(guān)鍵技術(shù)環(huán)節(jié)。本文將探討一套結(jié)構(gòu)清晰、易于實(shí)施的簡單方案,旨在為中小型團(tuán)隊(duì)或項(xiàng)目提供切實(shí)可行的實(shí)踐路徑。
一、 實(shí)時日志收集方案
實(shí)時收集是數(shù)據(jù)流水線的起點(diǎn),核心目標(biāo)是低延遲、高可靠地將分散在各服務(wù)器、容器或終端上的日志數(shù)據(jù)匯聚到統(tǒng)一的數(shù)據(jù)中樞。
- 日志產(chǎn)生與格式化:應(yīng)用代碼應(yīng)遵循結(jié)構(gòu)化日志規(guī)范(如JSON格式)輸出日志,包含時間戳、日志級別、服務(wù)名、請求ID、關(guān)鍵業(yè)務(wù)參數(shù)等固定字段,這為后續(xù)的解析和處理奠定基礎(chǔ)。
- 收集代理部署:在每臺數(shù)據(jù)源服務(wù)器上,部署輕量級的日志收集代理。Fluentd 或 Filebeat 是兩款優(yōu)秀的選擇。它們負(fù)責(zé)持續(xù)監(jiān)控指定的日志文件或直接接收應(yīng)用通過TCP/UDP發(fā)送的日志流,進(jìn)行初步的過濾、解析(如將JSON字符串解析為結(jié)構(gòu)化字段)和標(biāo)簽標(biāo)記。
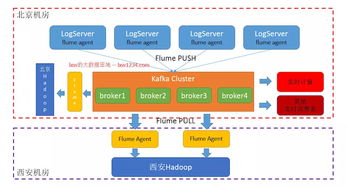
- 消息隊(duì)列緩沖:收集代理將處理后的日志事件,以高吞吐、低延遲的方式發(fā)送至一個中心化的消息隊(duì)列進(jìn)行緩沖。Apache Kafka 或 RabbitMQ 在此環(huán)節(jié)扮演核心角色。消息隊(duì)列解耦了數(shù)據(jù)生產(chǎn)(收集)與消費(fèi)(計算),能有效應(yīng)對數(shù)據(jù)量激增帶來的峰值壓力,保證數(shù)據(jù)不丟失,并為多個下游消費(fèi)者提供支持。
二、 實(shí)時計算方案
實(shí)時計算負(fù)責(zé)對持續(xù)流入的日志流進(jìn)行即時處理與分析,快速產(chǎn)出業(yè)務(wù)價值。
- 流處理引擎消費(fèi):實(shí)時計算任務(wù)由流處理引擎從消息隊(duì)列(如Kafka)中訂閱并消費(fèi)日志流。Apache Flink 和 Apache Spark Streaming 是當(dāng)前主流的選擇。Flink因其真正的流處理模型、極低的延遲和強(qiáng)大的狀態(tài)管理,在實(shí)時性要求極高的場景中尤為突出。
- 核心計算邏輯:在流處理引擎中,我們可以定義一系列計算任務(wù):
- 實(shí)時ETL:對原始日志進(jìn)行清洗、格式化、豐富(如關(guān)聯(lián)用戶畫像數(shù)據(jù))。
- 實(shí)時聚合統(tǒng)計:例如,按時間窗口(每分鐘、每5分鐘)統(tǒng)計PV/UV、接口調(diào)用次數(shù)與平均耗時、錯誤碼分布等。
- 實(shí)時監(jiān)控告警:定義規(guī)則(如錯誤日志率在1分鐘內(nèi)超過5%),實(shí)時檢測并觸發(fā)告警(對接釘釘、企業(yè)微信或短信通道)。
- 實(shí)時特征計算:為在線推薦或風(fēng)控系統(tǒng)實(shí)時生成用戶的最新行為特征。
- 結(jié)果輸出與存儲:計算產(chǎn)生的結(jié)果需要被持久化或推送給下游服務(wù):
- 實(shí)時可視化:將聚合指標(biāo)寫入時序數(shù)據(jù)庫(如 InfluxDB、TDengine)或支持快速查詢的OLAP數(shù)據(jù)庫(如 ClickHouse),供Grafana等儀表板工具實(shí)時展示。
- 實(shí)時服務(wù):將處理后的消息或預(yù)警事件直接推送到業(yè)務(wù)服務(wù)或消息通知系統(tǒng)。
- 長期存儲:將原始的或清洗后的日志批量存入數(shù)據(jù)湖(如HDFS、S3)或Elasticsearch,供離線深度分析與歷史追溯。
三、 簡單架構(gòu)示例
一個典型的輕量級架構(gòu)鏈路可概括為:應(yīng)用程序 -> (輸出結(jié)構(gòu)化日志) -> Filebeat/Fluentd -> (收集轉(zhuǎn)發(fā)) -> Kafka -> (緩沖分發(fā)) -> Flink Job -> (實(shí)時計算) -> ClickHouse/Grafana (展示) & Elasticsearch (檢索) & 告警通道。
四、 關(guān)鍵考量與優(yōu)化點(diǎn)
可靠性:確保消息隊(duì)列和流處理任務(wù)具備高可用性,關(guān)鍵業(yè)務(wù)數(shù)據(jù)考慮Exactly-Once語義。
可擴(kuò)展性:各組件均應(yīng)支持水平擴(kuò)展,以應(yīng)對數(shù)據(jù)規(guī)模的增長。
運(yùn)維監(jiān)控:對數(shù)據(jù)流水線本身(如Kafka堆積、Flink Checkpoint狀態(tài))進(jìn)行監(jiān)控,保障其穩(wěn)定運(yùn)行。
成本與復(fù)雜度:對于初創(chuàng)團(tuán)隊(duì),可以從云服務(wù)商提供的托管日志服務(wù)(如AWS Kinesis、阿里云SLS)起步,以降低運(yùn)維負(fù)擔(dān)。
構(gòu)建互聯(lián)網(wǎng)日志的實(shí)時收集與計算能力,并非一蹴而就。從核心的“收集-緩沖-計算-輸出”閉環(huán)入手,選擇成熟、適配的技術(shù)組件,并隨著業(yè)務(wù)發(fā)展逐步迭代優(yōu)化,是邁向數(shù)據(jù)實(shí)時化的一條穩(wěn)健路徑。這套方案為快速構(gòu)建數(shù)據(jù)驅(qū)動的實(shí)時業(yè)務(wù)反饋循環(huán)提供了堅(jiān)實(shí)的基礎(chǔ)框架。